Tags
What is Natural Language Processing? A Short Guide for Regular People
To achieve the best user experience possible, Wingbot.ai has developed our own natural language processing (NLP) pipeline, which best suits our chatbot engines and drives better understanding rates. Natural Language Processing is a branch of computer science generally only understood in depth by nerds. We've tried to explain it here.
Natural Language Processing
how bots understand what you mean
To truly understand a language like a human does, a computer system needs to recognize not only the meaning of individual words but also the relationships between those words. Natural Language Processing (NLP) is the branch of computer science - or more specifically artificial intelligence - concerned with giving computers this power.
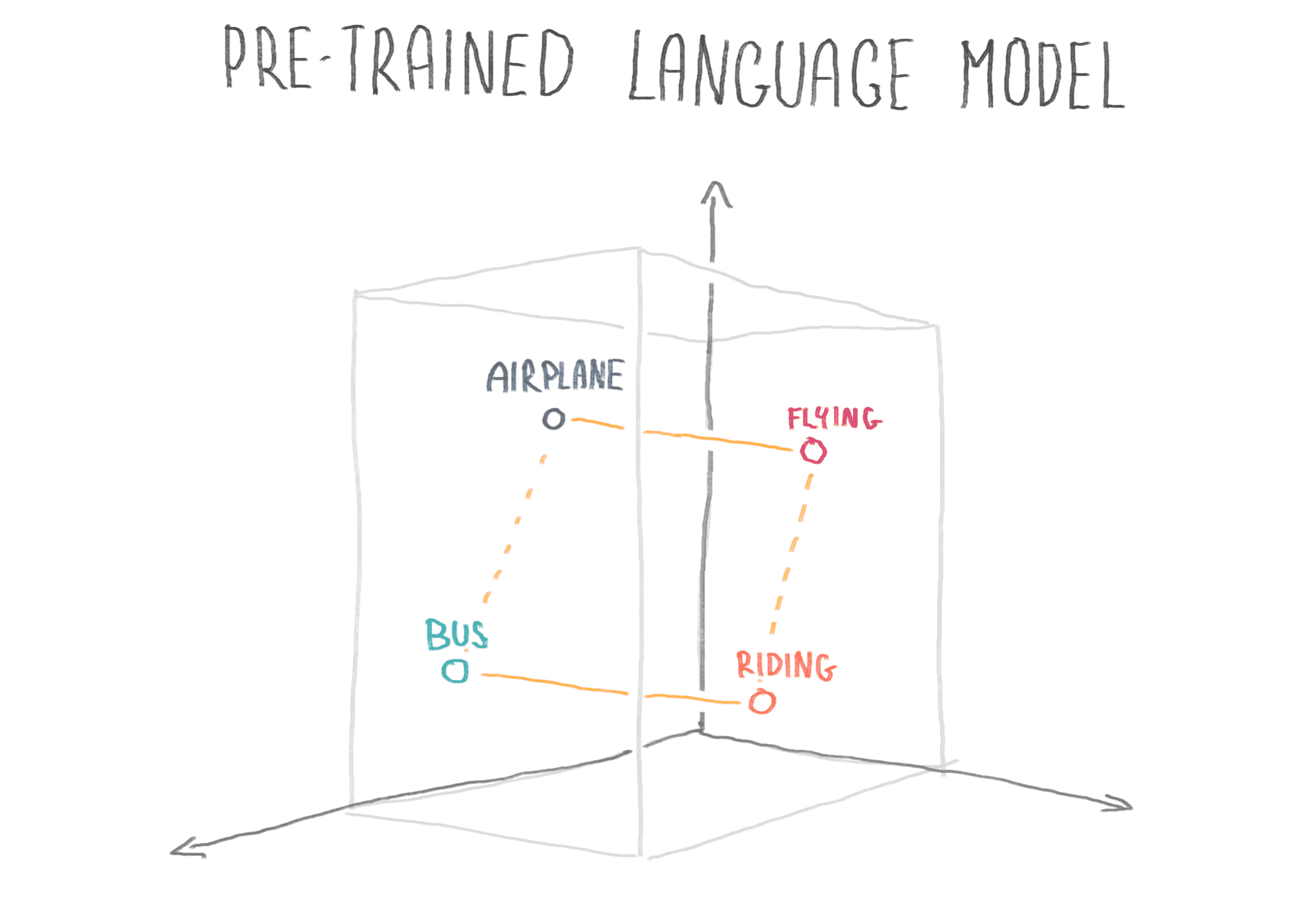
The foundational basis of Natural Language Processing (NLP) is a process called word embedding. All pre-trained NLP models use it, even and especially ChatGPT. It gives every word a numeric representation and places it in a multi-dimensional space according to its meaning.
Wingbot's NLP model specifically uses a branch of word embedding called word2vec. It's an extremely powerful tool with huge implications for NLP science, and it has advanced significantly in the past few years due to the groundbreaking research of computer scientist Tomas Mikolov, from Wingbot's native Czech Republic.
"word2vec"
How word2vec works is: When the Wingbot team is training a custom language model, we "map" the training data onto the pre-trained model's space and extract a subset of related words from its dictionary. We're then able to determine a numeric representation of each training sample and use this data to train a neural network. Neural network training is like establishing imaginary borders between words according to which intent they belong to. Our head engineer drew a little graphic that explains:
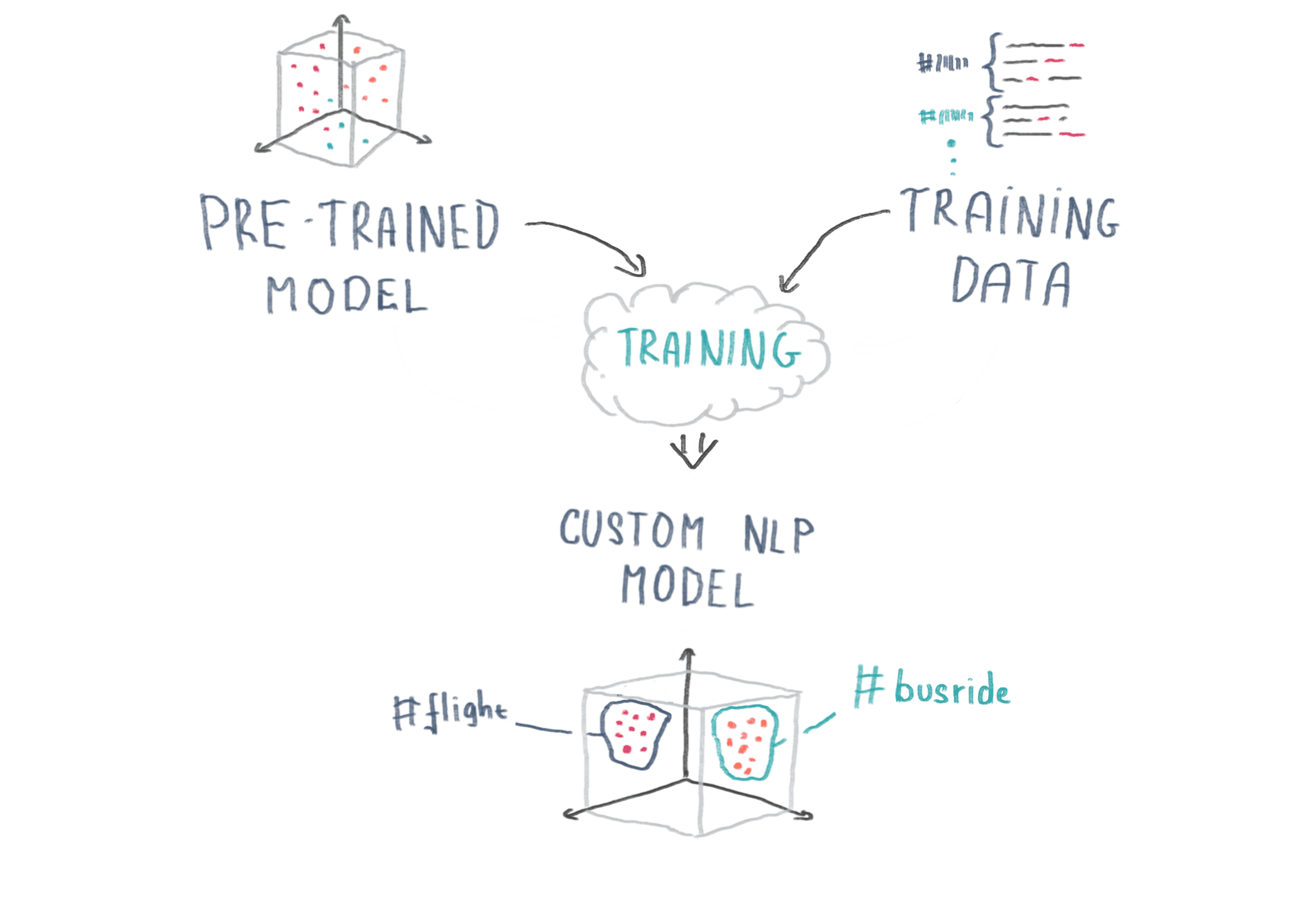
Training a custom NLP model with intent examples
What does it mean to train an AI system? For a chatbot to be able to understand your question and its specific intent, we need to provide sample phrases and their meanings: these are called intents. Sometimes there is a need to detect a specific type of information, for example a city - we call this an entity.
Intent samples + marked entities = training data.
It's kind of like learning how to ride a bike, but involving a lot of math. Fortunately at Wingbot we do it for you :)
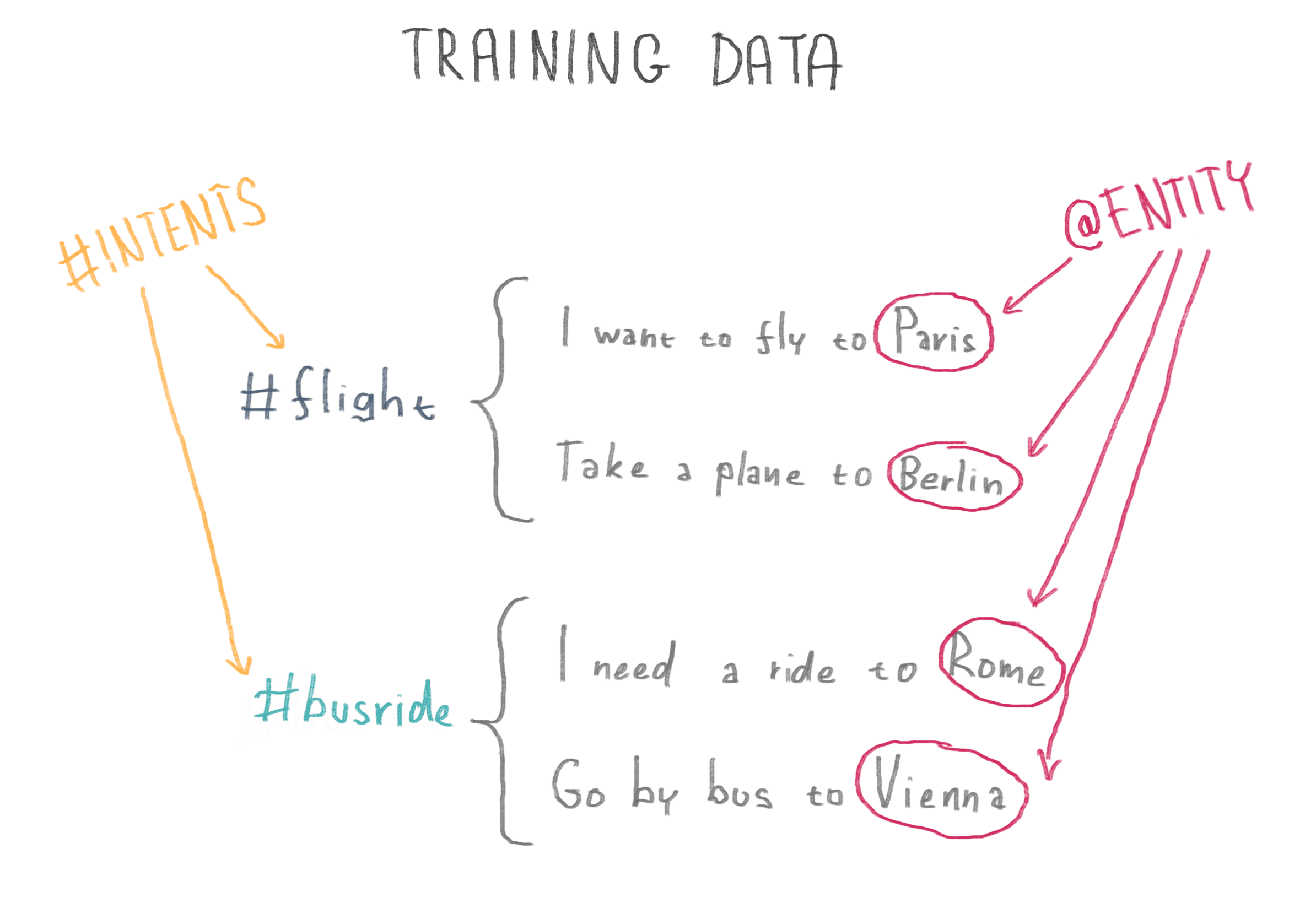
Detecting intents and entities
When you ask our chatbot to find a flight, it will first detect all possibly correct entities - words that match with pre-defined lists or rule sets, like numbers, dates or cities. Then the NLP will try to find a numeric representation of your sentence by determining its coordinates in the the NLP model. By translating the sentence to numbers we can use the previously trained neural network to recognize the winning intent and confidence of recognition. You find the best flight for you, and everyone is happy.

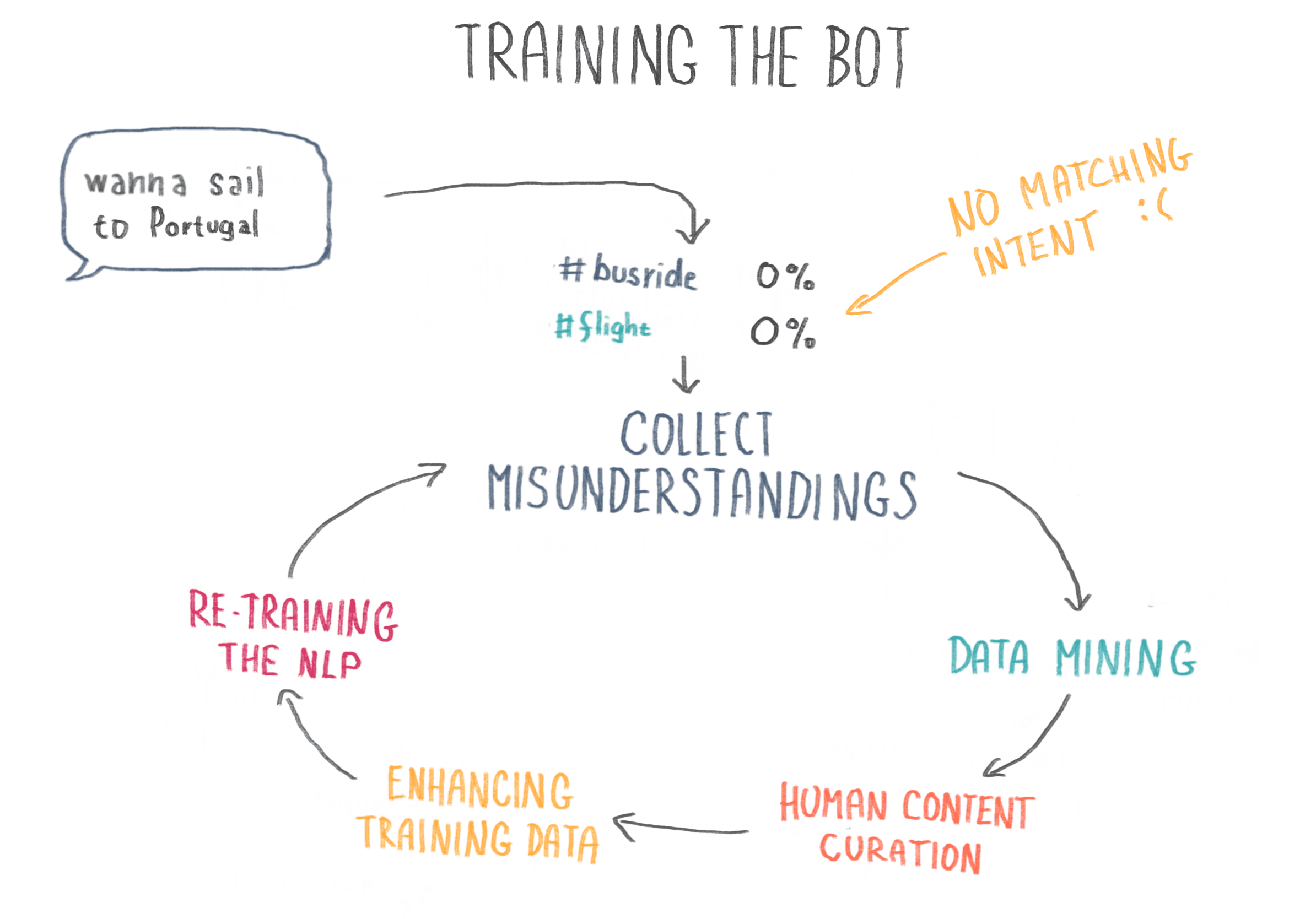
How the chatbot learns
Sometimes you ask a chatbot a question and it responds with something like "Sorry, can you rephrase that?" or simply "I don't understand." This can be frustrating, but remember - the chatbot you're communicating with is likely just a child. And like a child, every misunderstanding teaches it an important lesson.
When a Wingbot fails to understand a user's query, this failure is flagged to a member of our team (a trained computer scientist and human being) to be analyzed. The findings of this analysis are then used to carefully curate more refined training data - a new topic, for example, or a new list of entities. This is called "human curation" and not every chatbot company does it, but we think it powers better results :) Only with regular and continuous training can an NLP-powered bot achieve high understanding rates.